Vision and Language
The ability to process vision takes up more of the human brain than any other function, and language is our primary means of communication. Any robot that is going to communicate flexibly about the world with a human will inevitably need to relate vision and language in much the same way that humans do.
Team Members
Anton van den Hengel
University of Adelaide, Australia
Prof van den Hengel and his team have developed world leading methods in a range of areas within Computer Vision and Machine learning, including methods which have placed first on a variety of international leader boards such as: PASCAL VOC (2015 & 2016), CityScapes (2016 & 2017), Virginia Tech VQA (2016 & 2017), and the Microsoft COCO Captioning Challenge (2016).
Prof van den Hengel’s team placed 4th in the ImageNet detection challenge in 2015 ahead of Google, Intel, Oxford, CMU and Baidu, and 2nd in ImageNet Scene Parsing in 2016. ImageNet is one of the most hotly contested challenges in Computer Vision.
Stephen Gould
Australian National University (ANU), Australia
Stephen Gould is a Professor in the Research School of Computer Science in the College of Engineering and Computer Science at the Australian National University. He received his BSc degree in mathematics and computer science and BE degree in electrical engineering from the University of Sydney in 1994 and 1996, respectively. He received his MS degree in electrical engineering from Stanford University in 1998. He then worked in industry for a number of years where he co-founded Sensory Networks, which sold to Intel in 2013. In 2005 he returned to PhD studies and earned his PhD degree from Stanford University in 2010. His research interests include computer and robotic vision, machine learning, probabilistic graphical models, deep learning and optimization.
In 2017, Steve spent a year in Seattle leading a team of computer vision researchers and engineers at Amazon before returning to Australia in 2018.
Chunhua Shen
University of Adelaide, Australia
Chunhua Shen is a Professor at School of Computer Science, University of Adelaide. He is also an adjunct Professor of Data Science and AI at Monash University.
Prior to that, he was with the computer vision program at NICTA (National ICT Australia), Canberra Research Laboratory for about six years. His research interests are in the intersection of computer vision and statistical machine learning. He studied at Nanjing University, at Australian National University, and received his PhD degree from the University of Adelaide. From 2012 to 2016, he held an Australian Research Council Future Fellowship. He is Associate Editor (AE) of the Pattern Recognition journal, IEEE Transactions on Circuits and Systems for Video Technology; and served as AEs for a few journals including IEEE Transactions on Neural Networks and Learning Systems.
Anthony Dick
University of Adelaide, Australia
Anthony is an Associate Professor at The University of Adelaide’s School of Computer Science. He holds a Bachelors of Mathematics and Computer Science (Hons) from the University of Adelaide and received his PhD from the University of Cambridge in 2001. Anthony’s interest areas include computer vision: that is, the problem of teaching computers how to see. He is interested in tracking lots of people or objects at once, and in building 3D models from video. (Over 2,400 citations and an h-index of 24).
Yuankai Qi
University of Adelaide, Australia
Yuankai is a postdoctoral research fellow based at The University of Adelaide. He is working with Prof. Anton van den Hengel and Dr. Qi Wu. Yuankai received his B.E, M.S, and Ph.D. degrees from Harbin Institute of Technology in 2011, 2013 and 2018 respectively.
His research is focused on computer vision tasks especially visual object tracking and instance-level video segmentation. He is currently doing research on the vision and language navigation task.
Hui Li
University of Adelaide
Hui Li completed her PhD in 2018 at The University of Adelaide under the supervision of Chief Investigator Chunhua Shen and Associate Investigator Qi Wu. She received a Dean’s Commendation for Doctoral Thesis Excellence. Hui’s research interests include visual question answering, text detection and recognition, car license plate detection and recognition, and also deep learning techniques. She became a Research Fellow with the Centre in July 2018.
Violetta Shevchenko
University of Adelaide
Violetta joined the Centre as a PhD researcher in 2018. She received her Bachelor Degree in Computer Science at Southern Federal University, Russia, in 2015. After that, Violetta participated in a Double Degree program with Lappeenranta University of Technology in Finland, where she finished her Masters in Computational Engineering in 2017. Her research interests lie in computer vision and deep learning and, in particular, in solving the task of visual question answering.
Yicong Hong
Australian National University (ANU), Australia
Yicong completed his Bachelor of Engineering at the Australian National University in 2018, majoring in Mechatronic Systems. He was a research student at Data61/CSIRO from 2017 to 2018 working on his honours project about human shape and pose estimation. Yicong joined the Centre as a PhD researcher in 2019 under the supervision of Chief Investigator Professor Stephen Gould. His research insterests include visual grounding and textual grounding problems and he is currently working in the Centre’s Vision and Language research project.
Zheyuan ‘David’ Liu
Australian National University (ANU), Australia
David graduated from the Australian National University in 2018 with first class honours in Bachelor of Engineering (Research and Development), majoring in Electronics and Communication Systems and minoring in Mechatronics Systems. David joined the Centre in 2019 as a PhD student at ANU under the supervision of Chief Investigator Professor Stephen Gould. His research interests surround vision and language tasks in the field of Deep Learning, particularly visual grounding and reasoning.
Sam Bahrami
University of Adelaide, Australia
Sam is a Research Programmer who comes from a software engineering background, having worked in both technology and defence companies throughout Australia. As a research programmer, he is working on implementing solutions for novel navigation behaviour for robots and self driving cars based on deep machine learning.
Sam has a Bachelor of Engineering (Electrical & Electronic) Honours and a Bachelor of Mathematics & Computer Science from the University of Adelaide.
Project Aim
The ability to process vision takes up more of the human brain than any other function, and language is our primary means of communication. Any robot that is going to communicate flexibly about the world with a human will inevitably need to relate vision and language in much the same way that humans do. It’s not that this is the best way to sense, or communicate, only that it’s the human way, and communicating with humans is central to what robots need to be able to do.
This project uses technology developed for vision and language purposes to develop capabilities relevant to visual robotics. This is more than just Visual Question and Answering (VQA) for robots or Dialogue for Tasking. It includes questions of what needs to be learned, stored, and reasoned over for a robot to be able to carry out a general task specified by a human through natural language.
Key Results
In 2019, the project team extended the Room2Room dataset to evaluate a robot’s ability to identify a specific, household object in another room. For example, a cup, spoon or pillow. This provided a new task and dataset called REVERIE (Remote Embodied Visual referring Expression in Real Indoor Environments), which has been submitted to the 2020 Conference on Computer Vision and Pattern Recognition (CVPR). This is a significant step towards the ‘Bring me a spoon’ challenge, and an important extension of the existing dataset because it develops the challenge from merely navigating to the right location to identifying a specific object in a particular location. The project team plans to complete the ‘Bring me a spoon’ challenge (via simulation) in 2020.
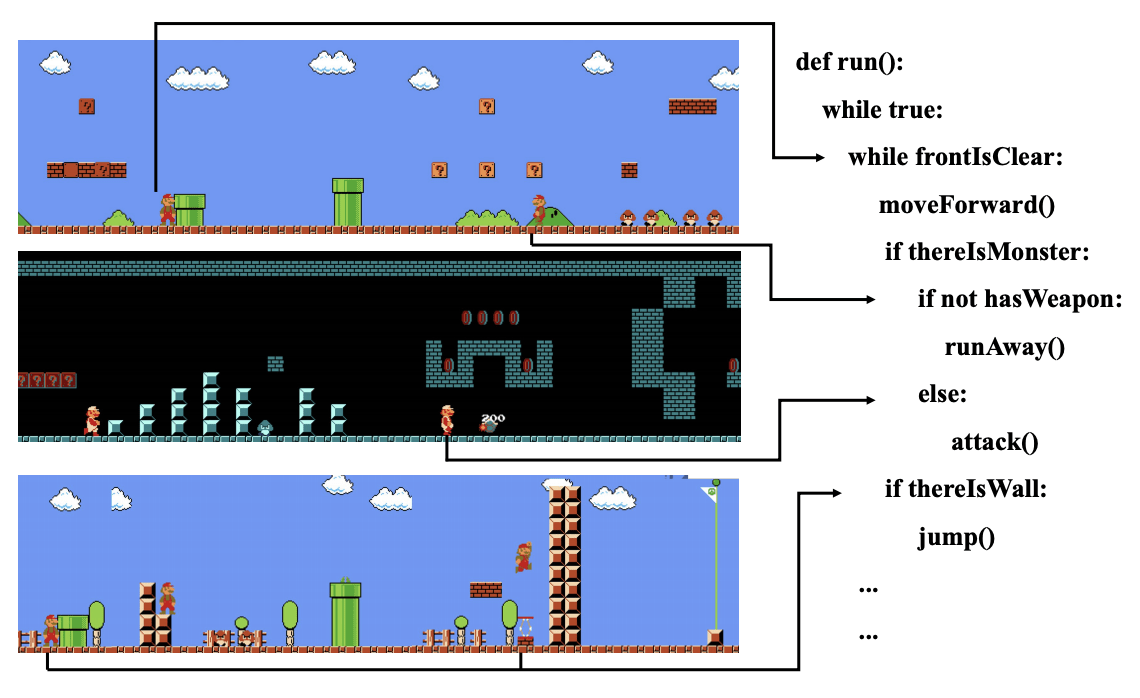
The team proposed an Object-and-Action Aware Model for Robust Visual-and-Language Navigation (VLN). VLN is unique in that it requires turning relatively general natural language commands into actions on the basis of the visible environment. This requires extracting value from two very different types of natural language information: action specifications (describing movements the robot must achieve) and object descriptions (specifying items visible in the environment). The proposed approach is to process these two different forms of natural language-based instruction separately. This research is important because a robot can perform correct actions only after it fully understands both visual and semantic information. It has been submitted to the Meeting of the Association for Computational Linguistics (ACL 2020)
The project team proposed a novel deep learning-based model – a Sub-Instruction Aware Vision-and-Language Navigation model – which focuses on the granularity of visual and language sequences as well as the trackability of robots through completion of instruction. In this model, robots are provided with fine-grained annotationsduring training, and found to be able to better follow the instruction and have a greater chance of reaching the target at test time. This work has also been submitted to ACL 2020.
The team proposed a Visual Question Answering (VQA) model with Prior Class Semantics that can deal with out-of-domain answers for VQA problems. Out-of-domain answers are those that have never been seen before in the training set. This involved presentation of a novel mechanism to embed prior knowledge in a VQA model.The open-set nature of the task is at odds with the ubiquitous approach of training a fixed classifier. The project team showed how to exploit additional information pertaining to the semantics of candidate answers, and extended the answer prediction process with a regression objective in a semantic space (in which candidate answers were projected using prior knowledge derived from word embeddings).
Finally, the project team developed a demonstrator on a robotic arm (UR5 by Universal Robots) at the Centre’s University of Adelaide node. The robotic arm followed natural language instruction to draw a human face.
Activity Plan for 2020
- Develop a robust and state-of-the-art model for vision-language-navigation and our new task REVERIE (Remote Embodied Visual Referring Expression in Real Indoor Environment).
- Develop a demonstrator on the robotic arm located at the Centre’s University of Adelaide node. The team has demonstrated V2L technology previously on the Pepper robot. This demonstrator will extend this work, with the aim of enabling a robotic arm to follow novel natural language instructions.
- Develop technology to enable a robot to identify information that it needs to specify and then complete its task. Moving from VQA into Visual Dialogue will provide the capability to ask questions that seek information necessary to complete a task, and to identify when enough information has been gathered and an action should be taken.
{kind=link}
{kind=link}
{kind=link}
{kind=link}