
Understanding: Semantic Representations
The Semantic Representations (SR) program develops models, representations and learning algorithms that will allow robots to reason about their visual percepts, describe what they see and plan actions accordingly. The representations explored in this program will enable the recognition of activities from observer and actor viewpoints, fine-grained understanding of human-object, object-object and robot-object interactions and large-scale semantic maps of environments. The program also investigates the mapping of visual inputs to sequence outputs for achieving a given task (e.g., describing a scene textually or providing a symbolic representation for a robotic task based on human demonstration).
SR projects
SR1—VIDEO REPRESENTATIONS
Research leader: Basura Fernando (RF)
Research team: Stephen Gould (CI), Gordon Wyeth (CI), Anoop Cherian (RF), Sareh Shirazi (RF), Fahimeh Rezazadegan (PhD), Rodrigo Santa Cruz (PhD), Bohan Zhuang (PhD)
Project aim: Part of robots’ understanding and interacting with their surrounds and humans is being able to operate in a dynamic environment. This project considers ways in which videos or short video segments can be represented usefully for robots, plus ways they can monitor, understand and predict the actions and interactions of a human. It also explores ways robots can use video feed to predict the consequences of their actions. The Video representations project extends these elements further to investigate how robots can learn from observation and an understanding of dynamic scenes to work on collaborative or cooperative tasks.
SR3—SCENE UNDERSTANDING FOR ROBOTIC VISION
Research leader: Niko Sünderhauf (CI)
Research team: Tom Drummond (CI), Michael Milford (CI), Ian Reid (CI), Feras Dayoub (RF), Yasir Latif (RF), Trung Thanh Pham (RF), Ming Cai (PhD), Mehdi Hosseinzadeh (PhD), Kejie Li (PhD), William Hooper (PhD) Lachlan Nicholson (PhD), Saroj Weerasekera (PhD), Huangying Zhan (PhD)
Project aim: For many robotic applications, understanding a scene comes from models of the environment that will give a robot information about geometric and semantic concepts and possible actions it can take (“affordances”).
The Scene understanding for robotic vision project is algorithms and representations for robots to acquire this contextual information, and make reasoned considerations about the uncertain and dynamic environments they are operating in.
As part of this work, the project has developed maps of the environment that are labelled semantically with a standard set of class labels, that are consistent and accurate within the scene’s 3D structure. We are investigating how we can use information from millions of examples to improve scene structures without having to impose hard constraints, like Manhattan world models. In addition to our other objectives, we are also providing semantic representations for the ACRV-SLAM project (AA2).
With these maps and labels established, we will develop representations that allow for a scene to be deconstructed, use the component parts for planning robotic navigation and acquisition or manipulation of objects. The representation of uncertainty is a key element of this project. While this is well understood in the context of geometry, our research question is how do we determine, represent and use uncertainty resulting from inference over semantic entities. The Scene understanding for robotic vision project draws on advances from the Fundamental Deep Learning project (VL1, finishing in 2017) to bridge this gap. As this project advances, we will move beyond simple labels to develop deeper, more powerful label sets, such as those describing affordances.
SR4—JOINT VISION AND LANGUAGE REPRESENTATIONS FOR ROBOTS
Research leader: Anton Van Den Hengel (CI)
Research team: Stephen Gould (CI), Chunhua Shen (CI), Anthony Dick (AI), Basura Fernando (RF), Chao Ma (RF), Qi Wu (RF), Peter Anderson (PhD)
Project aim: Unlike many computer vision tasks, which can be precisely circumscribed (e.g. image segmentation) robots in an open world must be able to learn and respond to unforeseen questions about unforeseen images, or develop action strategies for previously unseen circumstances.
The aim of this project is to build joint vision and language representations to describe scenes (captioning), answer queries (VQA), and describe and define robotic actions. The joint vision and language representations for robots project moves beyond natural language to consider more general image-to-sequence models, where a sequence may be intended as robot control commands.

Key Results in 2017
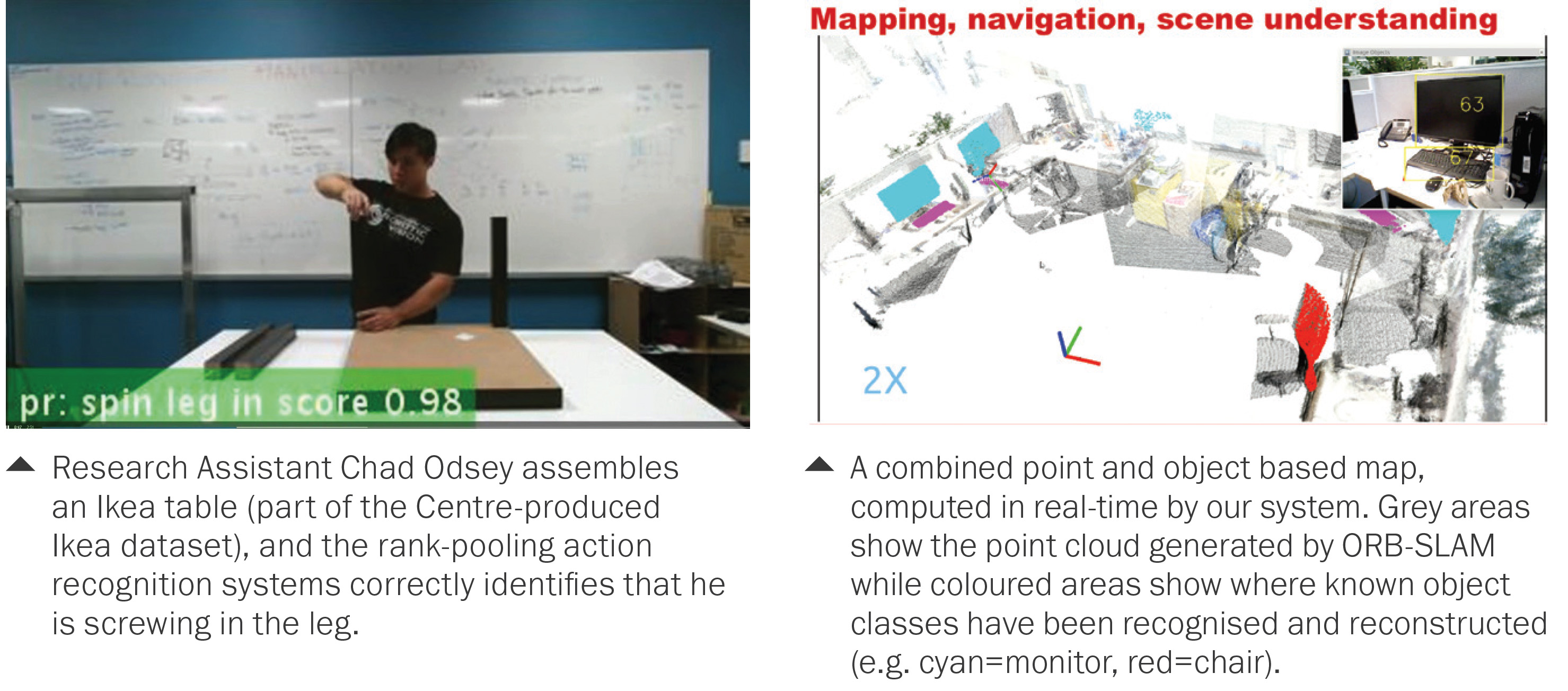
A novel rank pooling-based action recognition method was developed and evaluated by researchers at our ANU node in collaboration with QUT researchers. This has led to a real-time implementation that was deployed on the IKEA furniture dataset created by the team.
The system also delivers state-of-the-art performance on a number of public benchmarks and a number of papers were presented at the Conference on Computer Vision and Pattern Recognition (CVPR) 2017 and the International Conference on Computer Vision (ICCV) 2017. For example “Generalised Rank Pooling for Activity Recognition” by RF Anoop Cherian, RF Basura Fernando, Data61-CSIRO and ANU Senior Researcher Mehrtash Harandi and CI Stephen Gould was presented at CVPR.
Adelaide and Monash researchers delivered a new method for filling in depth based on uncertainty modelling in CNNs. This runs in real-time and can fill in parts of the scene where a dense or sparse depth sensor has not delivered a measurement. For example, in LIDAR it can be used for smart interpolation. For Kinect data it can fill in where holes arise from non-reflective objects or stereo shadows. The real-time implementation was used in the early prototype of the Amazon Challenge perception pipeline. The paper “Just-In-Time Reconstruction: Inpainting Sparse Maps using Single View Depth Predictors as Priors” by PhD Researcher Saroj Weerasekera, PhD Researcher Thanuja Dharmasiri, Associated Research Fellow Ravi Garg, CI Tom Drummond and CI Ian Reid has been accepted for the 2018 International Conference on Robotics and Automation (ICRA) to be held in Brisbane, Queensland.
An object-based semantic RGB-D SLAM was developed in a QUT and Adelaide collaboration. This real-time system maps the world (using ORB-SLAM) but recognises objects and reconstructs the objects in their own coordinate frame. The result is a map that comprises points and objects, with each object having a hi-fidelity geometric reconstruction.
This work builds on other work from the team on unsupervised scene segmentation, also used in the Amazon Challenge perception pipeline. The paper “Meaningful maps with object-oriented semantic mapping” by CI Niko Sünderhauf, RF Trung Pham, RF Yasir Latif, CI Michael Milford and CI Ian Reid was presented at the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) in Vancouver, Canada.
We continued development of integration of deep learning with SLAM, delivering the world’s first system that fuses dense geometry from a DTAM-like system via a prior provided from a deep learning system. More specifically, a deep network predicts the scene surface normals and these are used to regularise the geometry computed using more standard photometric consistency. A real-time system has been developed and demonstrated, and a licence is under negotiation with an Oxford start-up, 6Degrees-xyz. The paper “Dense monocular reconstruction using surface normal” by PhD Researcher Saroj Weerasekera, RF Yasir Latif, Associated RF Ravi Garg and CI Ian Reid was presented at the 2017 IEEE International Conference on Robotics and Automation (ICRA) in Singapore.
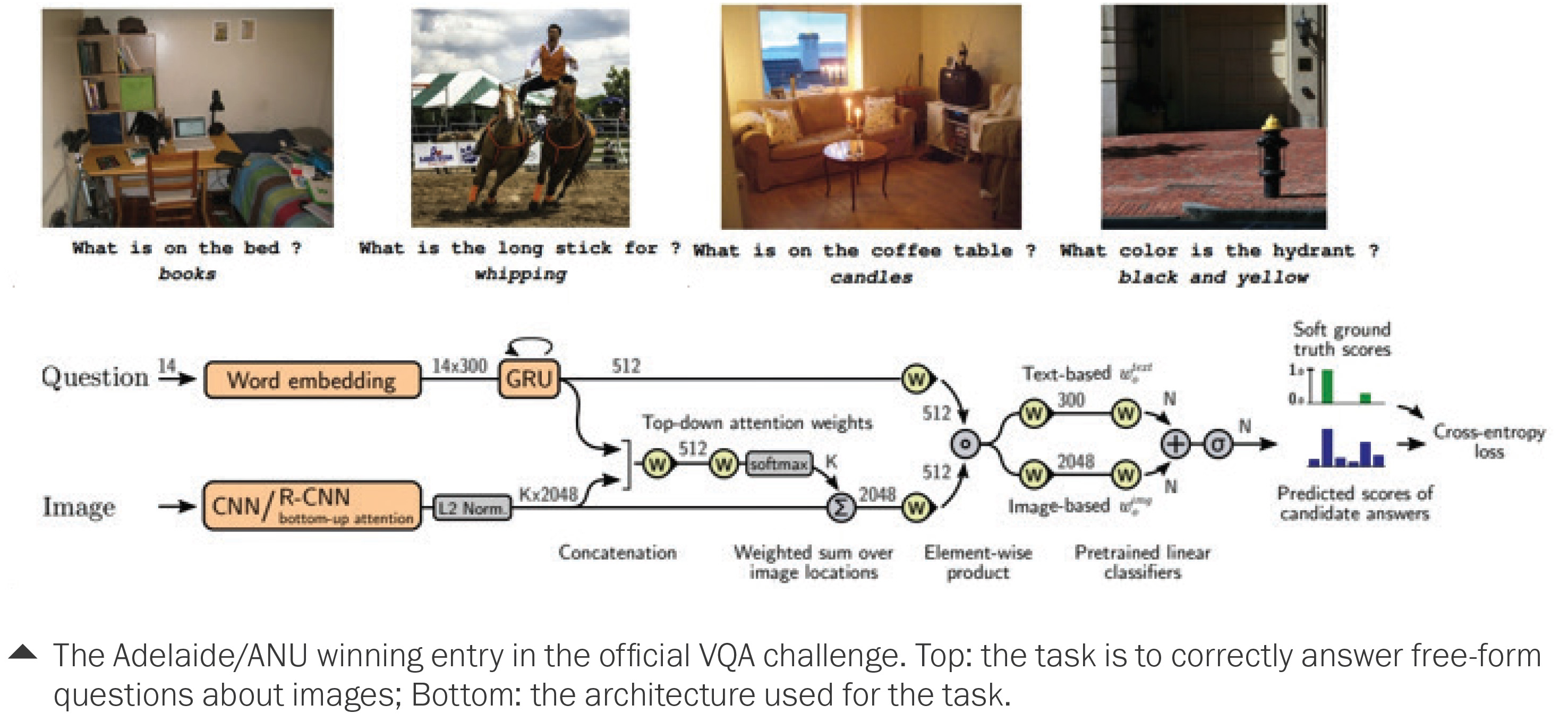
A system jointly developed between Adelaide and ANU was ranked 1st in the VQA Challenge 2017.
Visual Question Answering is an important stepping stone on the route to natural interaction with robots and this work is therefore germane to our efforts to integrate Vision and Language, for tasks such as Human-Robot interaction and for robotic navigation in a sematic space.
The paper “Tips and Tricks for Visual Question Answering: Learnings from the 2017 Challenge” by Adelaide PhD Researcher Damien Teney, PhD Researcher Peter Anderson, Xiaodong He and CI Anton van den Hengel was presented at the Computer Vision and Pattern Recognition (CVPR) conference workshop corresponding to the challenge in Hawaii, USA.